Categorizing Reddit Posts Based on their Titles
Objective:
The goal of this project is to use natural language processing to determine the subreddit based on the title of a post. The data includes all posts made to tech related subreddits in December 2016.
Data Exploration
I took a look at the distribution of the number of posts by subreddit and noticed that the dataset is disproportionally techsupport (we’ll deal with that later).
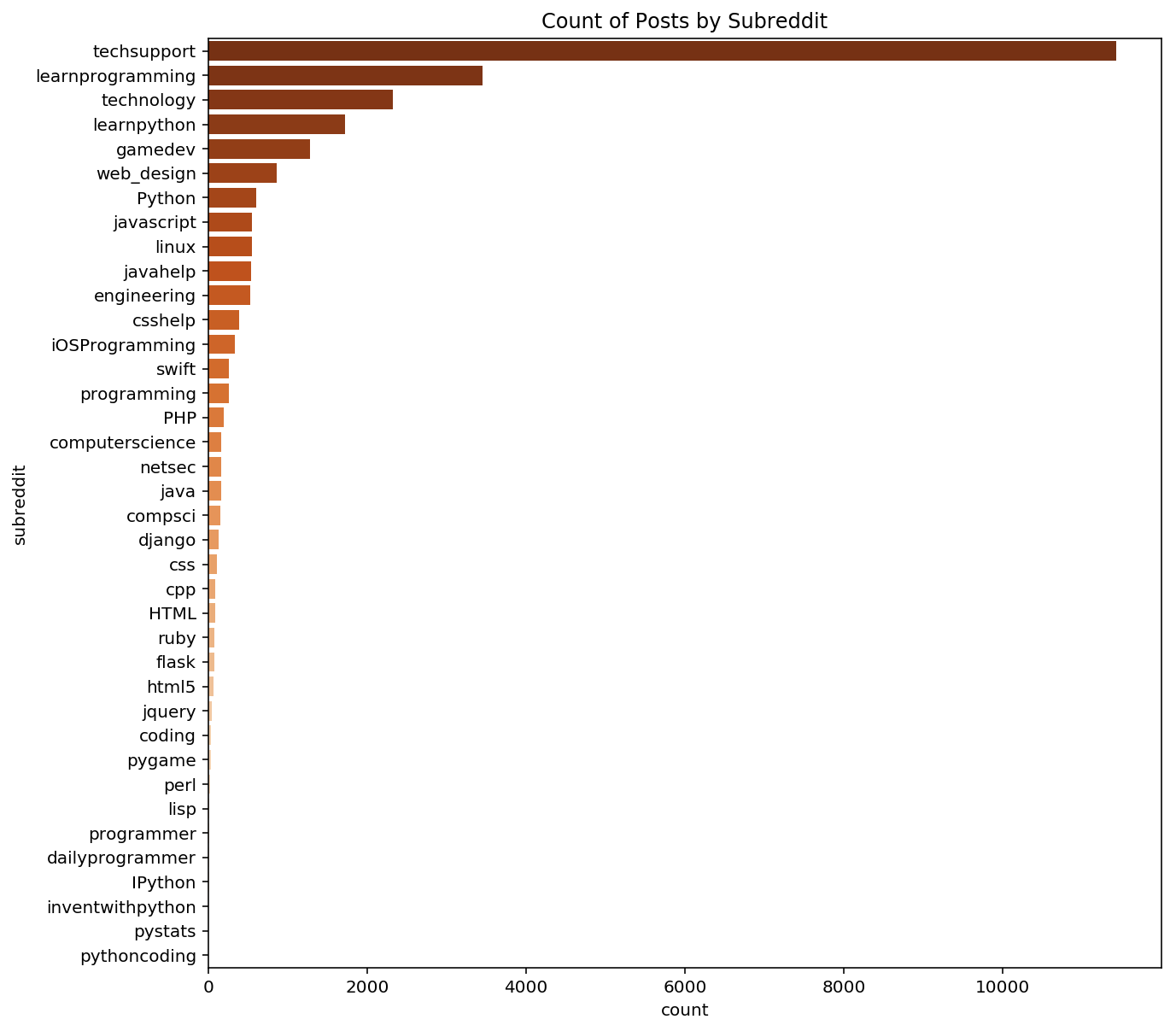
I grouped subreddits that have similar titles (ex: pythoncoding and Python) and kept the nine subreddits with most observations.
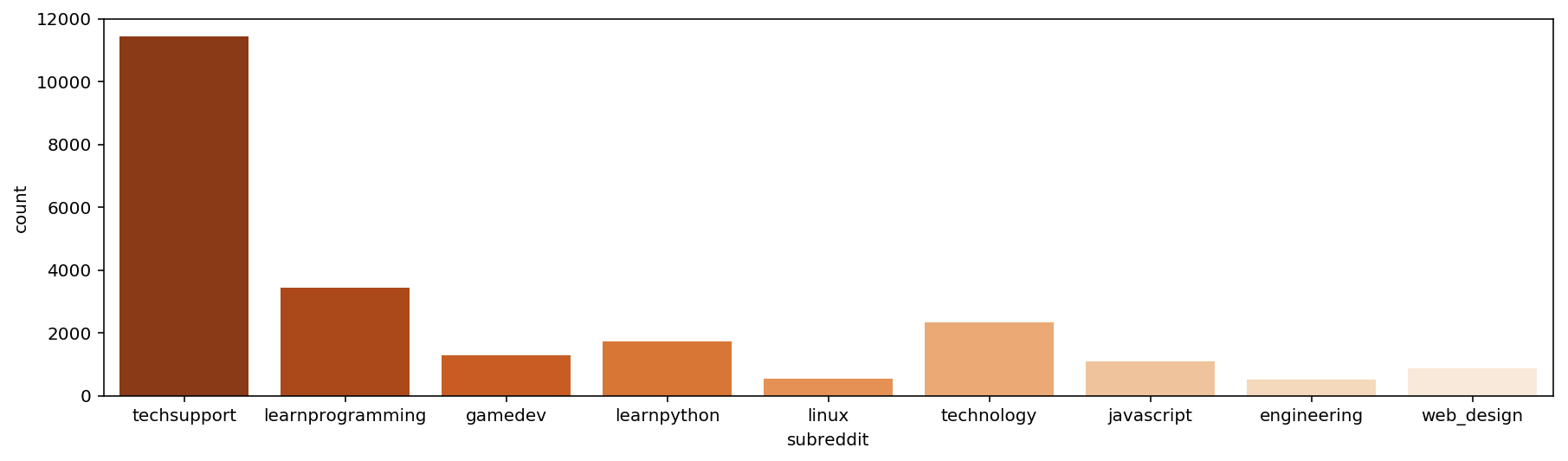
Data Cleaning/Preprosessing
The method of natural language processing used to clean the dataset was term frequency inverse document frequency (tfidf). Tfidf looks at the frequency of a certain word in each title with respect to the frequency of that word in the entire dataset. This technique reweights terms to strengthen those that are highly specific to a particular document, while suppressing terms that are common to most documents. Because the titles are only a few words long, we want to focus on words that are unique and therefore informative to our model.
Determine the Baseline
Before we can evaluate whether our classifier’s accuracy is good or bad, we need to know the baseline accuracy. The baseline accuracy is the proportion of the majority class. It tells us the how often out model would be correct if it predicts that every observation belongs to the majority class.
For this dataset the majority class is techsupport and the baseline is 0.429.
Modeling
The data set was split into a training set and a test set. The training set is used to fit the model and then test set is used to determine how well our model performs on unseen data. The tfidf preprocessed titles were fed into a random forest classifier model. The reults of the model are as follows:
The training & test score for the random forest model are 0.94 & 0.69 respectively. The score are larger than the baseline so we know that the model is doing more than just predicting all classes to be techsupport. However, there is a relatively large difference between the two scores so let’s dig a bit deeper to see how the model is really doing. To do this, we’ll look at the recall score in the classification report.
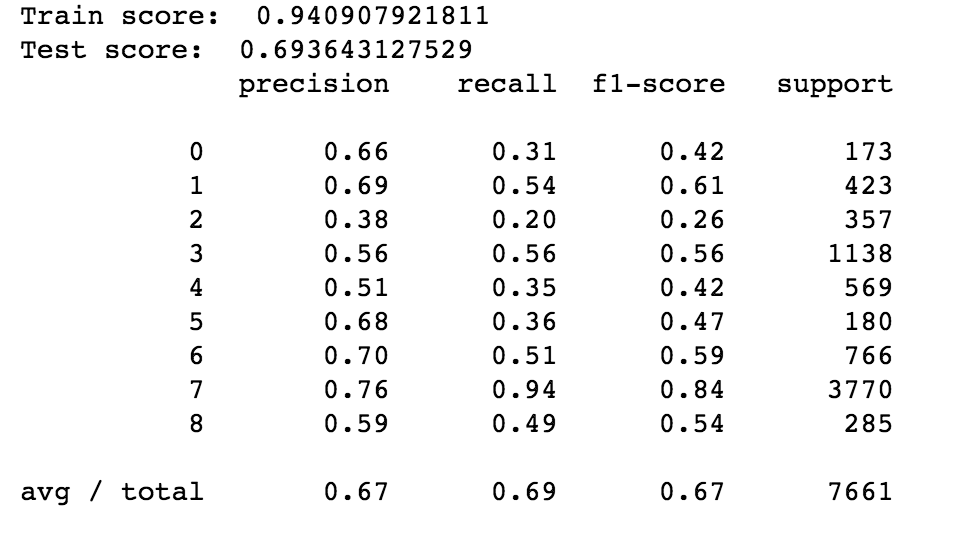
Looking at the classification report, we can see that the model is very good at predicting class 7 (techsupport) but not great at predicting everything else. We can visualize the predictions that the model has made with a heatmap.
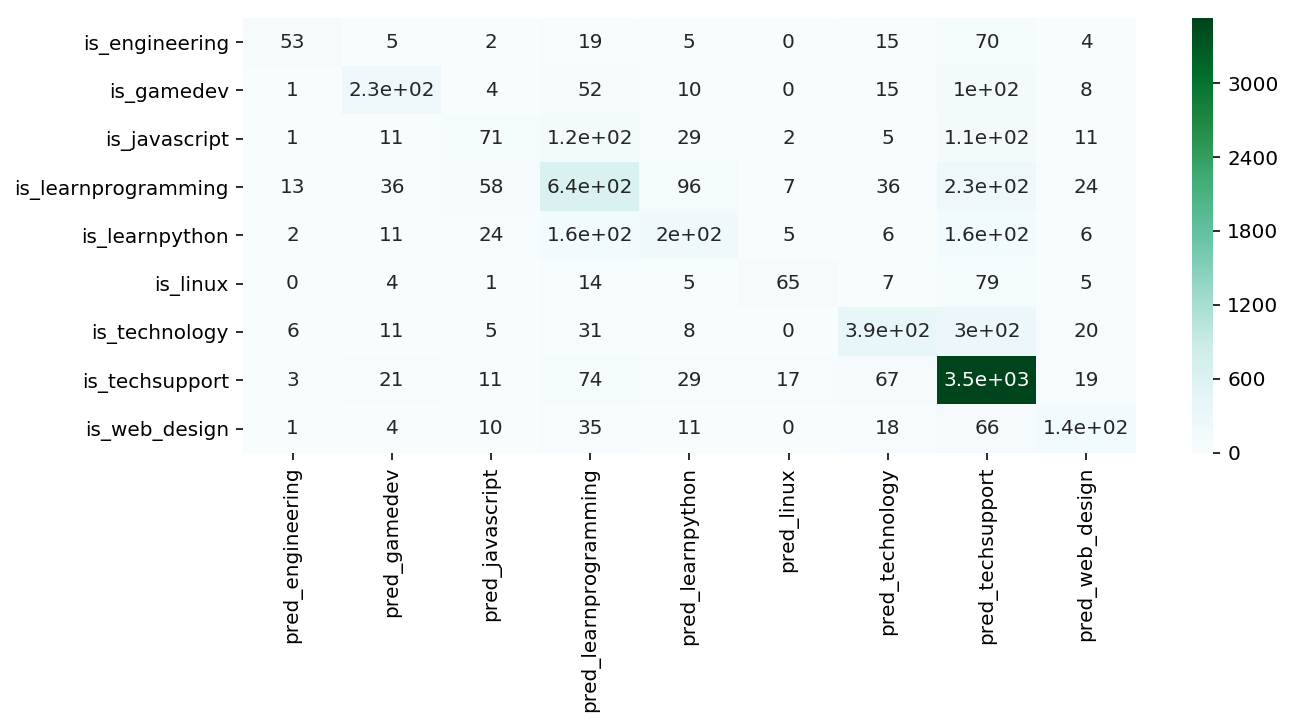
Resample Dataset
As mentioned previously, the dataset is disproportionately techsupport so I downsampled that category & learnprogramming using sklearn.utils.resample because it is more straightforward to use than something like SMOTE. I decreased the number of samples in the techsupport and learnprogramming classes to 2,500 samples. The resulting distribution of data is below:
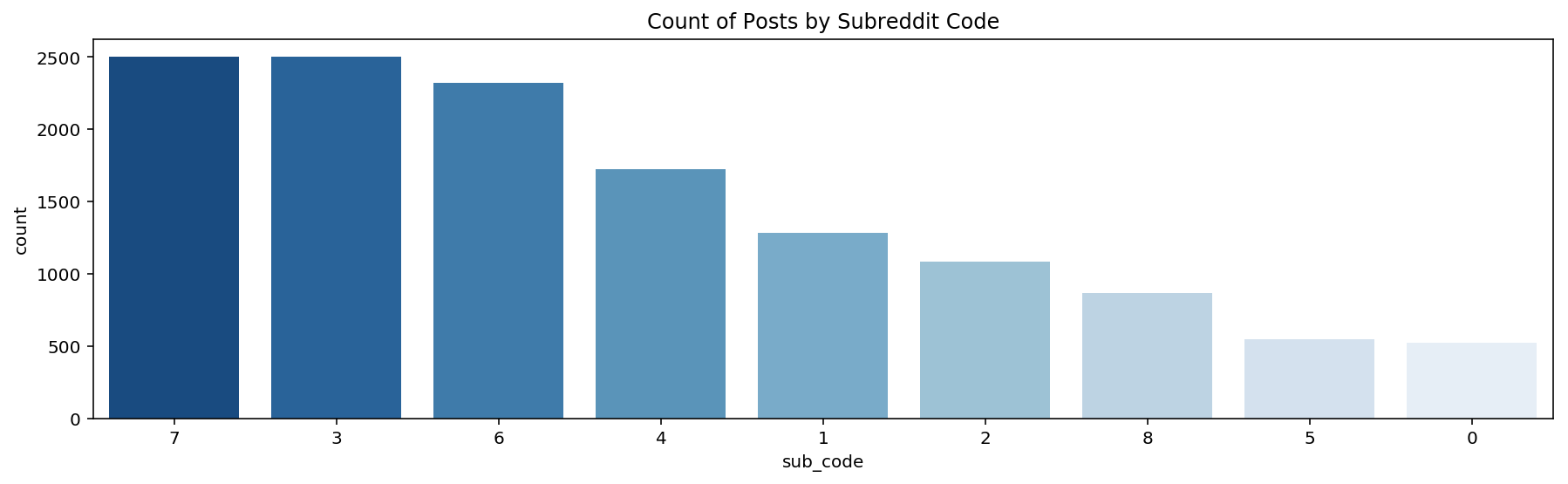
The baseline for the resampled test set is 0.187.
Resampled Modeling
The training & test score for the random forest model are 0.94 & 0.57 respectively. The test score is lower than that from the full dataset, but it has a larger distance from the downsampled baseline showing that this model is performing better than the original.
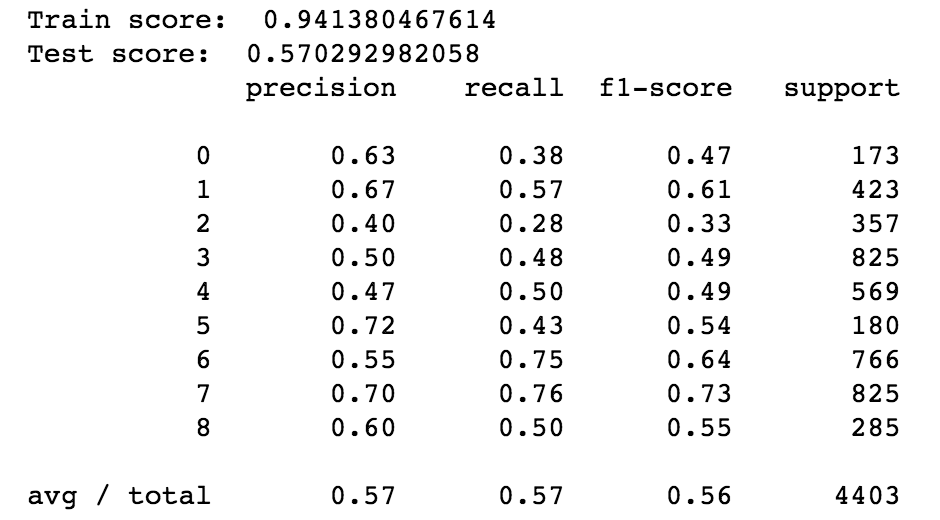
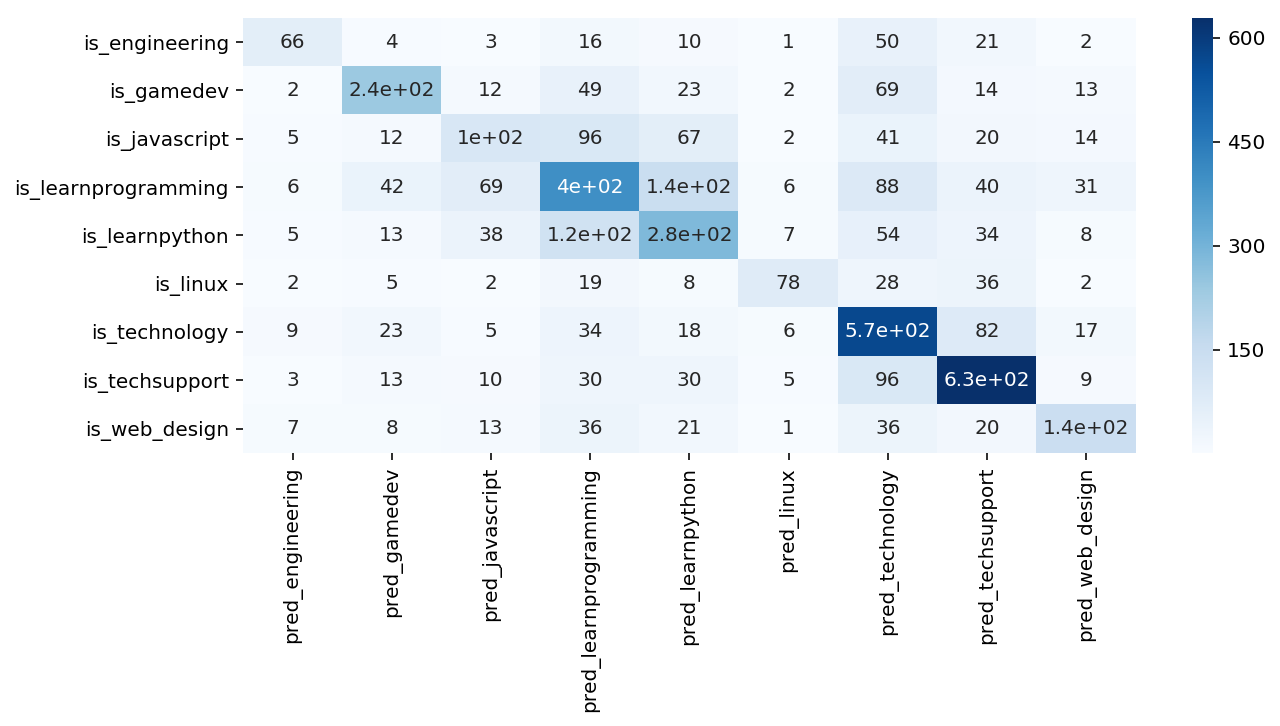
If we look at the classification report for the resampled dataset compared to the original dataset, we can see that it is much better at predicting all classes. There are, however, a non-negligible amount of missclassifications between learnprogramming and learnpython.
Word Frequency by Subreddit
Below is a visual representations of the word frequency for the top 20 words for each subreddit. Use the plots to determine common words that are found to understand the misclassifications in the model
If we look at the plotted words for learn programming and learn python we will see that there are a lot of overlapping words. In fact, the 4th most common word in the learn programming subreddit is python. The 1st and 2nd words, respectively, are help. The overlap between the most frequent words can explain the missclassification of titles belonging in learn programming as learn python and vice versa.

Next Steps
As the name implies Term Frequency Inverse Document Frequency can only look at how often a word occurs in a corpus. In order to improve the missclassifications due to commonly occuring words, I want to use Word2Vec to provide context to each word. I also want to look at different methods of resampling to see how that impacts the I specifically want to upsample the minority classes